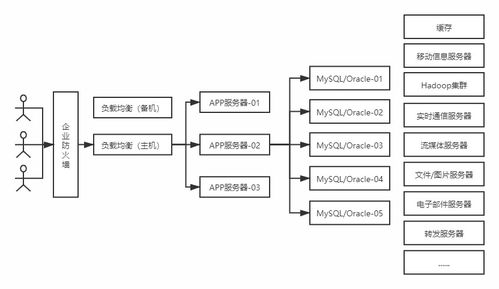
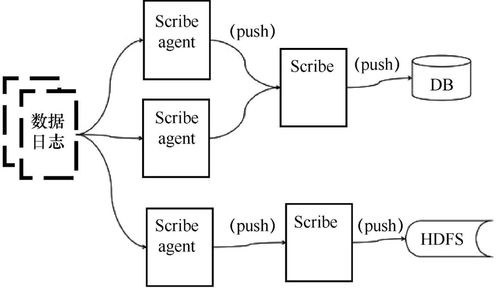
大數據采集工具及數據處理與存儲支持服務概覽
隨著大數據技術的快速發展,企業和組織對數據采集、處理和存儲的需求日益增長。本文將介紹常見的大數據采集工具,以及數據處理和存儲支持服務,幫助讀者全面了解相關技術選項。
一、大數據采集工具
大數據采集工具負責從各種來源(如數據庫、日志文件、傳感器、社交媒體等)收集數據,并將其傳輸到數據存儲或處理系統中。以下是幾類常用的大數據采集工具:
1. 日志采集工具:例如 Fluentd 和 Logstash,它們能夠從應用程序、服務器等收集日志數據,支持實時傳輸和過濾。
2. 數據同步工具:如 Apache Sqoop,專用于在 Hadoop 和關系型數據庫之間高效傳輸數據。
3. 流數據采集工具:例如 Apache Kafka,它作為分布式消息隊列,支持高吞吐量的實時數據流采集和發布。
4. Web 數據抓取工具:如 Scrapy 和 Apache Nutch,用于從網頁中爬取結構化數據。
5. 物聯網(IoT)數據采集工具:如 Apache NiFi,提供可視化界面,方便從傳感器和設備中采集數據。
這些工具通常支持多種數據格式和協議,并可集成到大數據生態系統中。
二、數據處理支持服務
數據處理服務負責對采集到的數據進行清洗、轉換、分析和計算,以提取有價值的信息。主要服務包括:
1. 批處理服務:例如 Apache Hadoop 的 MapReduce 和 Apache Spark,適用于大規模離線數據處理。
2. 流處理服務:如 Apache Flink 和 Apache Storm,支持實時數據處理和復雜事件處理。
3. 數據倉庫服務:例如 Amazon Redshift 和 Google BigQuery,提供快速查詢和分析結構化數據的能力。
4. 數據湖服務:如 AWS Lake Formation 和 Azure Data Lake,允許存儲和處理各種原始數據格式,支持機器學習和分析工作負載。
這些服務通常提供可擴展的計算資源、內置算法和用戶友好界面,幫助用戶高效處理數據。
三、數據存儲支持服務
數據存儲服務負責持久化存儲大數據,確保數據的安全性、可靠性和可訪問性。常見服務包括:
1. 分布式文件系統:例如 Hadoop HDFS,適合存儲大規模非結構化數據。
2. NoSQL 數據庫:如 MongoDB、Cassandra 和 HBase,用于存儲半結構化或非結構化數據,支持高并發訪問。
3. 云存儲服務:例如 Amazon S3、Google Cloud Storage 和 Azure Blob Storage,提供彈性、高可用的對象存儲方案。
4. 時序數據庫:如 InfluxDB,專為處理時間序列數據(如監控數據)設計。
5. 內存數據庫:如 Redis,適用于需要快速讀寫的場景。
這些存儲服務通常集成備份、加密和訪問控制功能,以滿足不同業務需求。
四、集成與最佳實踐
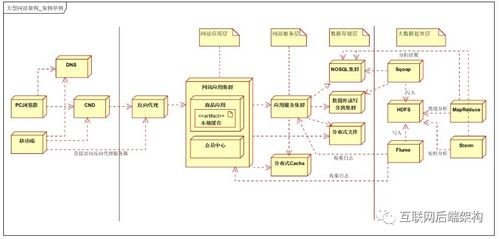
在實際應用中,大數據采集、處理和存儲服務往往需要集成使用。例如,可以使用 Apache Kafka 采集實時數據,通過 Apache Spark 進行流處理,然后將結果存儲到 Amazon S3 或 HBase 中。最佳實踐包括:
- 根據數據量、實時性和成本選擇合適工具和服務。
- 采用數據治理策略,確保數據質量和合規性。
- 利用云平臺(如 AWS、Azure 或 Google Cloud)的托管服務,簡化運維。
大數據生態系統提供了豐富的采集、處理和存儲工具與服務。通過合理選擇和組合,企業和組織能夠構建高效、可擴展的數據流水線,支持數據驅動的決策和創新。
如若轉載,請注明出處:http://m.fsqm.com.cn/product/2.html
更新時間:2026-01-12 23:16:25